To Clear Linux είναι γρήγορο, πολύ γρήγορο
Και όταν λέμε γρήγορο το εννοούμε ή εικόνα είναι από εδώ:
[center]
[/center]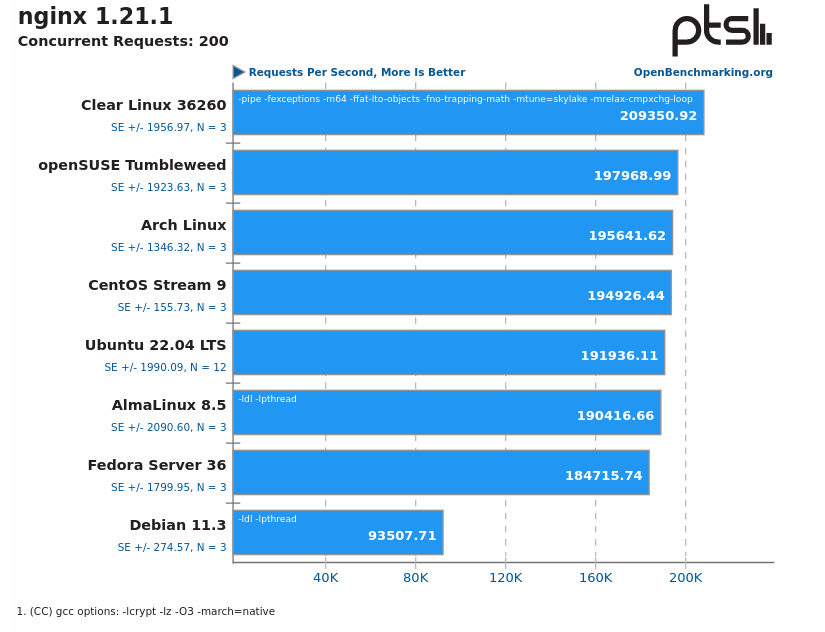
Σε σχέση με τα Windows 11 [πηγή]
[center]
[/center]
Δεν έχει σε όλα τα τεστ τόσο εξωφρενική διαφορά, αλλά έχει σε πολλά.
Το ερώτημα είναι τι το κάνει τόσο γρήγορο;
Γιατί είναι τόσο γρήγορο
Σύμφωνα με το ίδιο γιατί ακολουθεί μια ολιστική προσέγγισή στην απόδοση σε επίπεδο υλικού και λογισμικού. Ανταλλάζει (πολύ) μεγαλύτερους χρόνους στο compiling αλλά και στο μέγεθος του εκτελέσιμου για την απόδοση σε χρόνο εκτέλεσης. Η βελτιστοποίηση γίνετε για χρήση σε περιβάλλοντα server και cloud.
Μερικές τεχνικές που εφαρμόζει είναι οι εξής:
1. Βελτιώσεις στο compiling
Θα τρέξει μόνο σε επεξεργαστές της Intel μετά το έτος 2010 (αλλά έτρεξε μια χαρά και στον AMD που έχω). Θα θέσει march=westmere και mtune=haswell ένω θα κάνει compile με Ο3.
Το LTO Link-time optimization θα εφαρμοστεί στο τέλος της μεταγλώττισης. Αυτό κάνει μια επίμονα αργή ανάλυση του τελικού κώδικα για να τον κάνει καλύτερο. Το PGO Profile guided optimization θα βελτιστοποιήσει τον κώδικά χρησιμοποιόντας πληροφορία που συγκεντρώνει ο κώδικας κατα την εκτέλεση. Αυτό θα βελτιστοποιήσει τις συνηθέστερες διαδρομές εκτέλεσης.
2. Βελτιστοποιήσεις στον πυρήνα
Διαφορετικούς πυρήνες ανάλογα με το αν τρέχει bare metal η σε συγκεκριμένους τύπους VM. Ένα ειδικό εργαλείο θα βελτιστοποιήσει τις παραμέτρους του πυρήνα κατά την εκτέλεση. Χρήση peroformance governor που αξιοποιεί καλύτερα τα P-States του επεξεργαστή
3. Βιβλιοθήκες
Κάθε βιβλιοθήκη έχει χτιστεί πολλές φορές για διαφορετικές αρχιτεκτονικές. Η βιβλιοθήκη που θα χρησιμοποιηθεί θα επιλεχθεί δυναμικά για να ταιριάζει στο μοντέλο του επεξεργαστή. Υπάρχουν τρόποι να το κάνεις αυτό με τη βοήθεια του gcc, τόσο σε επίπεδο μεμονωμένης συνάρτησης, όπου γράφεις τον κώδικά πολλές φορές βελτιστοποιημένο σε επίπεδο αρχιτεκτονικής. Επίσης, μπορεί να γίνει σε επίπεδο Linker για ολόκληρη τη βιβλιοθήκη. Αν ενδιαφέρει μπορεί να το δούμε αυτό αναλυτικά κάποια στιγμή σε ένα άρθρο. Για μένα αυτό αλλάζει το παιγνίδι απέναντι σε source based διανομές.
Όπως βλέπετε είναι πολύ δουλειά, αλλά το αποτέλεσμα αξίζει.
Γιατί αυτές οι βελτιστοποιήσεις δεν εφαρμόζονται σε άλλες διανομές ;
Σε ένα πείραμα στο Phoronix προσπάθησαν να εφαρμόσουν κάποια τα παραπάνω σε ένα Ubuntu
[center]
[/center]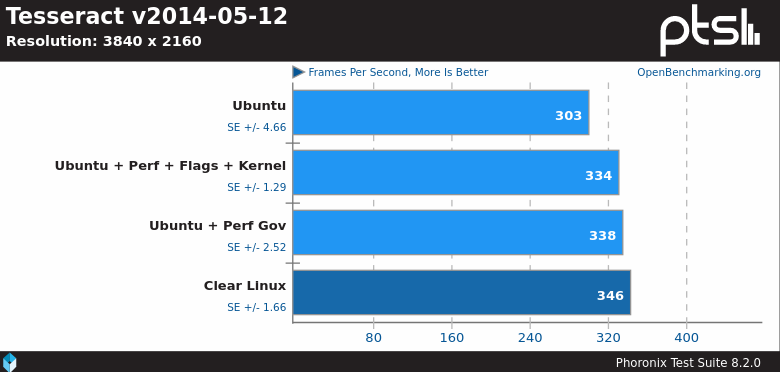
Τα αποτελέσματα ήταν ανάμεικτα αλλά πάντα οι βελτιστοποιήσεις βελτίωναν σημαντικά την απόδοση ενώ σε κάποιες περιπτώσεις το ξεπερνούσαν
Σε μια σημερινή ανάρτηση στο twitter γιατί το PopOS δε χρησιμοποιεί τις τεχνικές που χρησιμοποιεί το ClearLinux η απάντηση ήταν μονολεκτική: συμβατότητα.
Είναι όμως έτσι; Πράγματι, το ClearLinux απαιτεί αρκετά από τον επεξεργαστή, αλλά δεν έχω και τον τελευταίο, δεν έχω καν Intel και παίζει σε μένα μια Χαρά. Αλλά υπάρχει ένας επίσημος τρόπος να ελέγξουμε τον επεξεργαστή μας [πηγή]
curl -O https://cdn.download.clearlinux.org/current/clear-linux-check-config.sh
chmod +x clear-linux-check-config.sh
./clear-linux-check-config.sh host
./clear-linux-check-config.sh container
Στον υπολογιστή μου
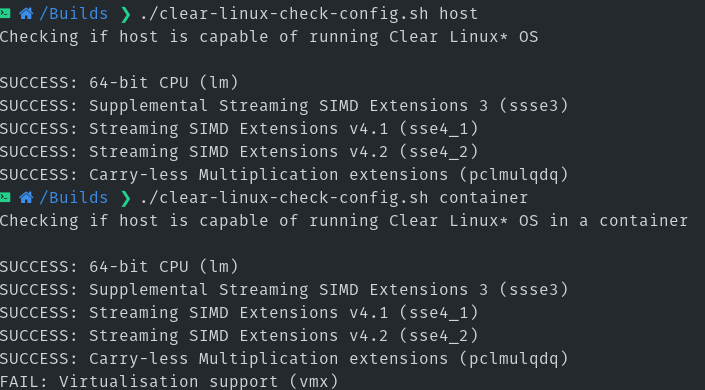
Είμαι περίεργος να μάθω αν τρέχει σε εσάς και αν όχι τι μοντέλο επεξεργαστή έχετε.
Σαν επίλογος
Η καινοτομία είναι εκεί έξω. Δε θα τη βρούμε σε διανομές που δε γουστάρουν systemd, wayland, ακόμα και το pam !!! κλπ. Θα τη βρούμε σε διανομές που προσπαθούν να επαναορίσουν τι σημαίνει μια μοντέρνα διανομή. Επίσης δεν βλέπω σήμερα κανένα νόημα σε source based διανομές δεν έχουν να προσφέρουν τίποτα, έκτος από αυξημένο λογαριασμό στη ΔΕΗ. Εσάς ποια είναι η γνώμη σας;
Δείτε ακόμα


