Ένας από του λόγους που το Chrome είναι ιδιαίτερα δημοφιλές ειδικά στην Ευρώπη είναι η δυνατότητα μετάφρασης ιστοσελίδων. Δεν είναι όλο το web στα αγγλικά και ένα ελάχιστο ποσοστό είναι διαθέσιμο στην Ελληνική γλώσσα. Οπότε αν ποτέ βρεθείς σε μια Γερμανική ή Ισπανική σελίδα η δυνατότητα αυτόματης μετάφρασης είναι πολύ χρήσιμη. Αλλά η αυτόματη μετάφραση σημαίνει πρόσδεση με τις υπηρεσίες της Google και αυτό δεν είναι δωρεάν, παρά μόνο στην τιμή. Αν το θέλεις θα πρέπει να χρησιμοποιείς Chrome ούτε καν τον Chromium.
Έχω εγκατεστημένο ένα Chrome για τις ελάχιστες περιπτώσεις που χρειάζομαι κάτι τέτοιο, καθώς και για ελάχιστα sites που απαιτούν τη χρήση DRM, όπως το Netflix ή το Viki.com. Αλλά απέχει από το να είναι η ιδανική λύση. Αν τουλάχιστον μπορούσα να έχω μια αξιοπρεπή μετάφραση έστω στα Αγγλικά στον Firefox …
Ε λοιπόν υπάρχει λύση. Και το καλύτερο όλων; Η μετάφραση γίνεται τοπικά χωρίς χρήση κάποιας εξωτερικής υπηρεσίας! Ναι, καλά ακούσατε! Δεν είναι τα πάντα που θέλουμε να μεταφράσουμε δημόσια, κάποια πράγματα καλό είναι να είναι προσβάσιμα μόνο για τα δικά μας μάτια.
Το ίδρυμα Mozilla σε συνεργασία με διάφορα Ευρωπαϊκά Πανεπιστήμια, και με τη χρηματοδότηση της Ευρωπαϊκής Ένωσης, ανακοίνωσε το έργο Project Bergamot το 2019 για να υποστηρίξει 24 απο τις 37 γλώσσες της Ευρώπης. Η πρώτη έκδοση υποστηρίζει 8 γλώσσες (δυστυχώς ανάμεσα τους δεν είναι η Ελληνική).
Εγκατάσταση
Είναι ένα επίσημο πρόσθετο του Firefox και το εγκαθιστούμε από εδώ:
Ελπίζω σύντομα να αποτελέσει επίσημο κομμάτι του Firefox.
Επίσης, για μικρά κείμενα είναι προσβάσιμο χωρίς εγκατάσταση από εδώ: Mozilla Translations. (Σε αυτή την περίπτωση θα χρησιμοποιηθεί μια υπηρεσία οπότε το κείμενο θα μεταφερθεί μέσα από το «καλώδιο»).
Τα μεταφραστικά μοντέλα είναι ανοικτού κώδικα και ελπίζω σύντομα να είναι διαθέσιμα μέσα από εξωτερικές βιβλιοθήκες και εργαλεία.
Χρήση
Σαν μια γρήγορη δοκιμή έκανα κλικ στο πρώτο άρθρο σε μια γερμανική εφημερίδα
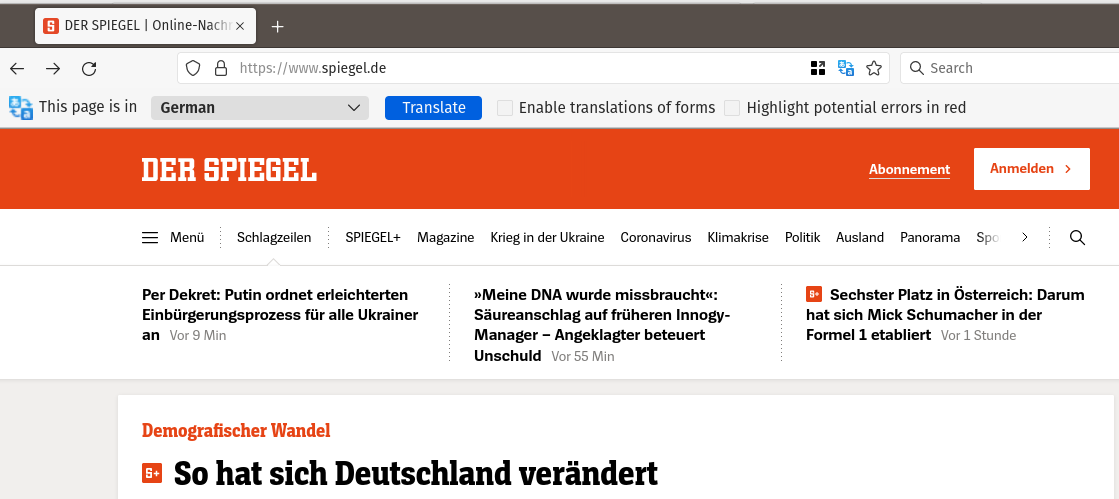
Η μετάφραση
This is how Germany changed
People live alone more often, take a high school diploma more often, retire later:
new data shows in detail how Germany has changed over the past three decades.
και το Chome
This is how Germany has changed
People live alone more often, take their Abitur more often and retire later:
New data show in detail how Germany has changed over the past three decades.
Δεν ξέρω Γερμανικά αλλά οι μεταφράσεις δείχνουν να είναι αρκετά καλές. Ελπίζω σύντομα εδώ να συγκρίνουμε τις διαφορές σε μεταφράσεις και στα Ελληνικά.
Πηγή: On-device browser translations with Firefox Translations | Ctrl blog