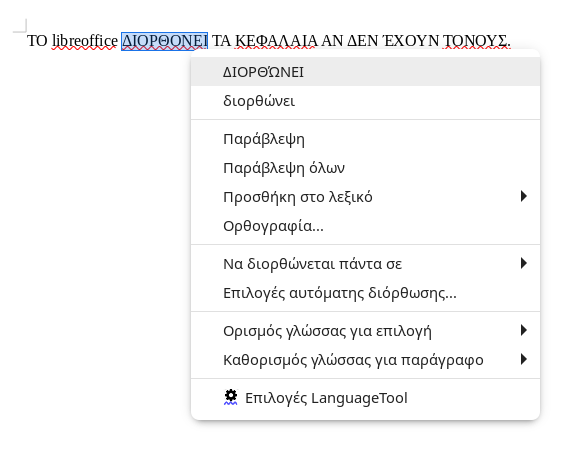
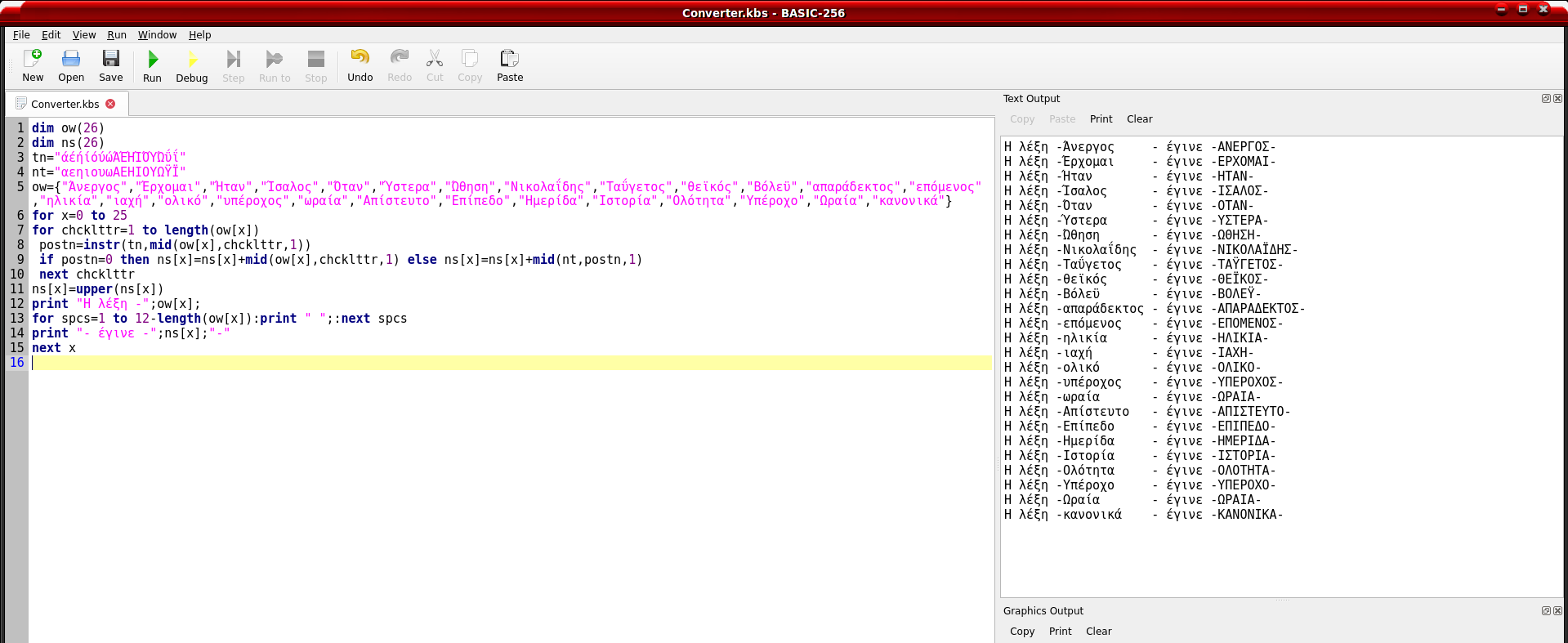
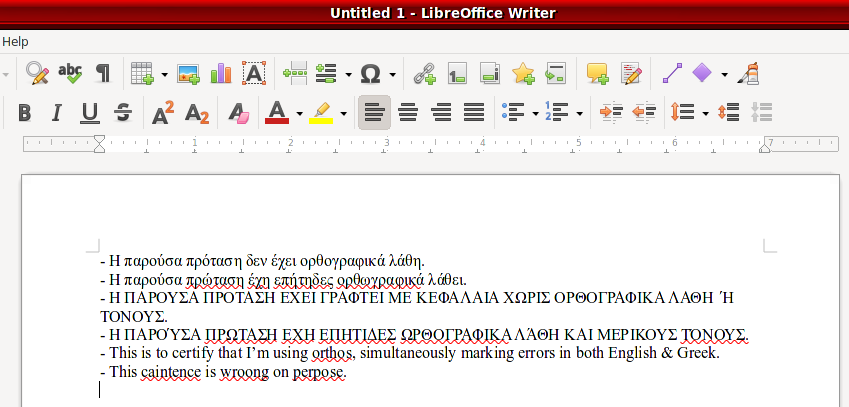
Όπως αναφέρω και στον τίτλο, το LibreOffice μαρκάρει τις λέξεις που είναι γραμμένες στα κεφαλαία ως λανθασμένες επειδή δεν έχουν τόνο. Έτσι, αν κάποια λέξη έχει ορθογραφικό λάθος το LibreOffice θα τη μαρκάρει με κόκκινο μαζί όμως και τις λέξεις που δεν έχουν ορθογραφικό λάθος. Αυτό είναι πρόβλημα γιατί ο χρήστης (εγώ) θα αγνοήσει όλα τα μαρκαρίσματα στα κεφαλαία και δε θα προσέξει το λάθος. Η αναμενόμενη και σωστή συμπεριφορά είναι να μαρκάρει μόνο τις λέξεις με λάθος και όχι αυτές που δεν έχουν τόνο (πάντα μιλώντας για λέξεις στα κεφαλαία) όπως δηλαδή το MS Office κάνει.
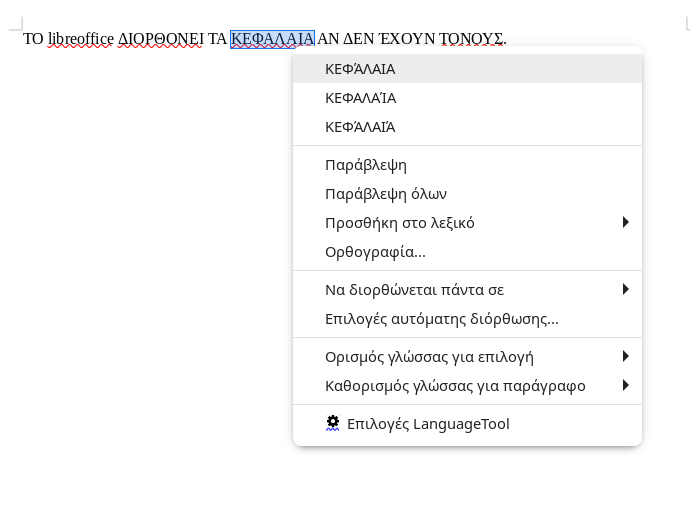
Δεν νομιζω να ειναι θεμα του LibreOffice αυτο μιας και στον Chromium κανει ακριβως τα ΙΔΙΑ. Παραθετω screenshot απο αυτο που σου γραφω τωρα για να δεις τι ακριβως εννοω. Η λεξη ΙΔΙΑ στο αριστερο μερος που ειναι με κεφαλαια 2 φορες ειναι και αυτη υπογραμμισμενη με κοκκινο σαν λαθος.
Το μονο workaround που θα μπορουσες να χρησιμοποιησεις σε αυτη την περιπτωση ειναι να προσθεσεις τις λεξεις με ΚΕΦΑΛΑΙΑ που θες στο λεξικο να μην λαμβανονται ως λαθος ετσι ωστε την επομενη φορα να μην υπογραμμιζονται.
Ωστόσο, μάλλον, αυτό δεν είναι θέμα του LibreOffice καθ´ αυτού αλλά του spell checker (Hunspell) που δεν μπορεί να κάνει διάκριση τον κανόνων στη περίπτωση που μια λέξη είναι μόνο κεφαλαία. Έτσι καθώς τα λεξικά έχουν όλες τις λέξεις με μικρά τονισμένες, αυτόματα θεωρεί τη λέξη σε κεφαλαία με τονισμό. Μια λύση είναι ένα λεξικό που έχει όλες τις λέξεις και με κεφαλαία χωρίς τόνους (OpenΟffice και Firefox), με εναπομένων πρόβλημα πως θεωρεί σωστή τόσο τη τονισμένη όσο και χωρίς λέξη με κεφαλαία. Η καλύτερη λύση θα ήταν το Hunspell να δέχονταν ή να μπορούσε να φτιαχτεί ένας κανόνας “μη τσεκάρει μια λέξη στα κεφαλαία για τονισμό.”
Καταλαβαίνω πώς το εννοείς αλλά δεν υπάρχει «θα έπρεπε». Με αυτό που λες, ουσιαστικά ζητάς από κάποιον άλλο να αφιερώσει χρόνο για να βάλει στο Hunspell χιλιάδες λέξεις στα κεφαλαία, και αυτός ο κάποιος θα πρέπει ταυτόχρονα να έχει επαφή με την ελληνική γλώσσα και -εφόσον μιλάμε για ελεύθερο λογισμικό- να μην πληρωθεί.
Αν σε καίει τόσο, μπορείς να ξεκινήσεις να συνεισφέρεις εσύ ή να προθυμοποιηθείς να πληρώσεις αυτόν που θα το κάνει.
Το ξέρω και το κατανοώ απόλυτα αυτό που λες σχετικά με τον κόπο (και την απουσία πληρωμής). Δεν απαιτώ, απλά αναφέρω το “παράπονό μου” που απαιτείτε παραπάνω χρόνος και κόπος από τον τελικό χρήστη για να λειτουργεί σωστά κάτι αρκετά βασικό κατά τη γνώμη μου. Η αλήθεια είναι πως δε θα άνοιγα καν αυτό το νήμα αν δεν ήταν το δικό σου σχετικά με το τι μας λείπει στο ελληνόγλωσσο ΕΛ/ΛΑΚ.
Έκανα ένα search στα issues στο Github και στα παλιά forums και mailing list στο SourceForge του Hunspell και δεν βρήκα καμιά αναφορά σε αυτό το θέμα, οπότε αφού κανένας δεν το ανέφερε λίγο δύσκολο να το γνωρίζουν. Για αρχή αν δεν βαριέσαι κάνε ένα reply στο bug report του LibreOffice που έδωσα λινκ παραπάνω με ότι ζητάει.
«Βασικό» είναι αποκλειστικά για όσους γράφουν Ελληνικά με κεφαλαία και ταυτόχρονα τους ενοχλεί τόσο πολύ να βλέπουν τις κόκκινες γραμμούλες και δεν προσθέτουν απλά τις λέξεις στο λεξικό τους. Δηλαδή για έναν απειροελάχιστο αριθμό χρηστών. Αν από αυτούς δεν έχει ασχοληθεί κανένας να βοηθήσει, πώς περιμένουμε να το κάνει κάποιος αλλόγλωσσος προγραμματιστής;
Σκέψου ότι έχουμε να κάνουμε με κάποιες χιλιάδες λέξεις, οι οποίες έχουν ενικό-πληθυντικό, πτώσεις, ενεργητική-παθητική φωνή και όλα αυτά. Και μετά μπαίνει στη μέση η κωδικοποίηση. Ούτε καν στα πεζά δεν είναι πλήρης ο έλεγχος και εμείς ζητάμε και τα κεφαλαία «τζάμπα και χωρίς κόπο»;
EDIT: Από την προσπάθεια που είχαν κάνει κάποτε, μια λίστα με 1.149.920 λέξεις σε πεζά και κεφαλαία χωρίς τόνους.
@Giannis-Arch Αυτό απλά ελέγχει/παύει να ελέγχει τις λέξεις με κεφαλαία σε οποιαδήποτε γλώσσα. Αν απενεργοποιηθεί, δε θα επισημαίνει ούτε τα κανονικά ορθογραφικά λάθη.
Αν το καταλαβαίνω σωστά, ένας αρθογράφος βασίζεται σε ένα αρχείο λέξεων. Προφανώς όμως δεν ξέρουν ότι στα Ελληνικά οι λέξεις με κεφαλαία δεν τονίζονται, ώστε να βγαίνει λάθος η τονισμένη λέξη και όχι το αντίθετο.
Αν κάποιος τους ενημερώσει, δεν θα μπορούσαν να σβήσουν ΟΛΕΣ τις λέξεις που περιέχονται στο λεξικό και είναι γραμμένες με κεφαλαία, και μετά να προσθέσουν μαζικά όσες έχουν με πεζά, με κάποια φόρμουλα μετατροπής σε κεφαλαία, όπως στο παράδειγμα της εικόνας;
@Georgie2 Το θέμα δεν είναι η ενημέρωση, γιατί έχει γίνει παλιότερα, αλλά το ότι δεν πρόκειται να χαραμίσει χρόνο ένας Άγγλος/Γάλλος/Πορτογάλος για να διορθώσει μια γλώσσα που δε γνωρίζει και δεν ομιλείται ευρέως στον πλανήτη. Θα πρέπει να είναι Έλληνας ή τουλάχιστον να έχει πολύ καλή γνώση των ελληνικών αυτός που θα ασχοληθεί, και ο τελευταίος που το έκανε ήταν το 2016.
Συν το ότι, αφενός μεν δεν υπάρχει κάποια λίστα με όλες τις λέξεις στα Ελληνικά (παραπάνω έδωσα μία που υπερβαίνει το εκατομμύριο και πάλι είναι ημιτελής), αφετέρου δε η κάθε λέξη πρέπει να είναι τουλάχιστον τριπλή (π.χ. ΙΤΑΛΟΣ - ΙΤΑΛΟΥ - ΙΤΑΛΟ, ενώ είναι δόκιμο και το ΙΤΑΛΟΝ στην αιτιατική, άρα τετραπλή εδώ).
Δεν έχω ιδέα πως και που να αναφέρω ένα πρόβλημα. Αν μπορείτε να με καθοδηγήσετε ευχαρίστως να το αναφέρω εκεί που πρέπει και όπως πρέπει. Το να προσθέτω στο λεξικό λέξεις είναι μια λύση που πρέπει να κάνω κάθε φορά που βάζω το LibreOffice και είναι μόνο για έμενα. Το ζητούμενο είναι να επιλυθεί μόνιμα και για όλους τους χρήστες.
Ίσως, αν μπορεί να προστεθεί κάποιος “κανόνας” που να χρησιμοποιεί το λεξικό με τις λέξεις στα πεζά για ορθογραφικό έλεγχο στα κεφαλαία αλλά να αγνοεί τον τόνο. Έτσι δε θα χρειαστεί να προστεθούν ξανά όλες οι λέξεις στα κεφαλαία αλλά με τα υπάρχοντα λεξικά να μη θεωρείτε λάθος η απουσία τόνων στα κεφαλαία.
Ο κώδικας του Hunspell είναι εδώ. Θα πρέπει να δημιουργήσεις λογαριασμό στο GitHub και να αναφέρεις ένα νέο issue. Educated guess: επειδή το Hunspell είναι απλά μια βιβλιοθήκη λογισμικού που διαβάζει λίστες λέξεων, πιθανότατα θα σου πουν να απευθυνθείς σε όποιον ασχολείται με την ελληνική λίστα… αν τον βρεις.
Δε δουλεύει έτσι. Για να κάνει ορθογραφικό έλεγχο το Hunspell συμβουλεύεται την ανάλογη λίστα κάθε γλώσσας. Αν μια λέξη δεν υπάρχει ακριβώς όπως έχει γραφτεί, τη μαρκάρει ως λανθασμένη και ψάχνει στη λίστα να βρει τη σωστή για να την προτείνει.
Επιπλέον, υπάρχουν και περιπτώσεις όπου η στίξη μπορεί να χρειάζεται σε κεφαλαίο γράμμα, όπως για παράδειγμα στο αριθμητικό Α’. Εκεί αυτός ο υποθετικός κανόνας θα γινόταν πολύπλοκος.
Το βασικό πρόβλημα είναι ότι τα Ελληνικά δεν ομιλούνται ευρέως, με αποτέλεσμα να ασχολούνται ελάχιστοι. Αυτός είναι και ο λόγος που αρκετά λογισμικά δεν έχουν ελληνική μετάφραση. Ξεκινάει κάποιος να κάνει κάτι, βλέπει ότι η «πλούσια» γλώσσα μας είναι βουνό και τα παρατάει.
Αυτό που βρίσκω στον υπολογιστή μου και νομίζω πως είναι το λεξικό στο οποίο βασίζεται ο ορθογράφος του Libreoffice, είναι το αρχείο el_GR-en_US.dic, στο
/usr/lib/libreoffice/share/extensions/orthos-el_GR-en_US/dicts
Το άνοιξα με nano, δεν μπορούσα να δω όλο το αρχείο με άλλο τρόπο.
Μετά από πολλή ώρα, μιας και το αρχείο είναι κι αυτό γύρω στα 20ΜΒ, έφτασα στην τελευταία λέξη, το “ωών”. Δεν βρήκα καμία λέξη με κεφαλαία.
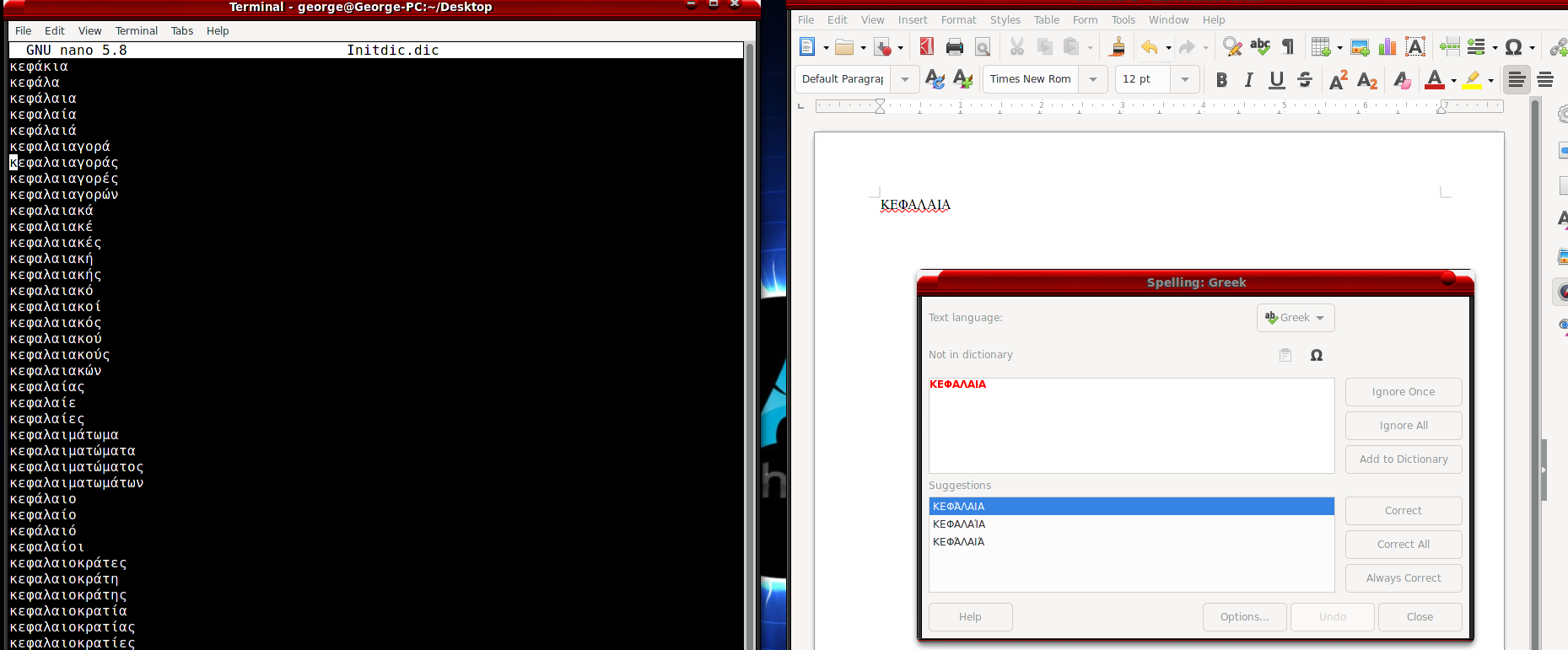
Κι επειδή η λέξη “ΚΕΦΑΛΑΙΑ” δόθηκε ως παράδειγμα παραπάνω, ορίστε και μια φωτό απ’ το συγκεκριμένο σημείο του αρχείου, με την ίδια πρόταση για διόρθωση στον κειμενογράφο.
Μάλλον κάπως αλλιώς δουλεύει η προτεινόμενη από τον αρθογράφο διόρθωση (με το μικρό μου το μυαλό λέω εγώ ότι βρίσκει την/τις αντίστοιχη/ες κοντινότερη/ες σε πεζά, και την/τις προτείνει σε “upper case” που λένε και στο χωριό μου). Αν έχω δίκιο, μάλλον κάπως αλλιώς πρέπει να προσεγγίσουμε το θέμα, όχι με προσθήκη λέξεων στα κεφαλαία.
Και το ξαναγράφω. Αφού η λέξη δεν υπάρχει με κεφαλαία, την ψάχνει με πεζά. Αφού λοιπόν βλέπει ότι ολόκληρη η λέξη είναι με κεφαλαία (και υπάρχει η ίδια με πεζά), ας την αφήσει χωρίς τόνο. Αν υπάρχει ορθογραφικό (δεν βρίσκει καθόλου τη λέξη) τότε ας τη μαρκάρει.
Εννοείται πως θα πρέπει να μαζέψουμε και κάποιους κανόνες που υπάρχουν και πρέπει να ληφθούν υπ’ όψη αν κάποιος αποφασίσει να το προχωρήσει. Αυτό που έγραψε ο @anon54176929 για τα αριθμητικά, εμένα θα μου ξέφευγε.
EDIT : Όσο για το ότι τα Ελληνικά δεν ομιλούνται ευρέως, σύμφωνα με τα γραφόμενα στο link για το Github που παρατέθηκε παραπάνω, ασχολούνται με πολύπλοκους συνδυασμούς ακόμα και για Φιννοουγγρικές γλώσσες, οι οποίες σύμφωνα με τη wikipedia ομιλούνται από περίπου 20 εκ. ανθρώπους.
Δε νομίζω ότι στέκει να αφήνουν απ’ έξω βασικό κανόνα της ελληνικής γραμματικής.
EDIT 2 : (Πρωινή φλασιά ξημερώματα Παρασκευής.)
Κανόνας : Πρώτο γράμμα κεφαλαίο (τονισμένο).
Στην εικόνα φαίνεται ότι οι λέξεις “άβακας” και “άβακα” υπάρχουν στο λεξικό μόνο με πεζά.
(Δεν είναι σε άλλη θέση, φαίνεται ξεκάθαρα στην αριστερή εικόνα πως η ταξινόμηση που έχει γίνει δεν λαμβάνει υπ’ όψη τον τόνο στο πρώτο γράμμα, ούτε αν είναι κεφαλαίο ή πεζό).
Αν δεν υπήρχε κανόνας μέσα στον ορθογράφο, πώς εξηγείται ότι δεν βγάζει τις λέξεις με κεφαλαίο, τονισμένο “Α”, λάθος;
Αντίθετα, η λέξη “Άβαι” που υπάρχει μόνο με κεφαλαίο τονισμένο “Α”, αν γραφτεί με πεζά μαρκάρεται ως λανθασμένη.
Άρα, κάποιοι κανόνες υπάρχουν, και κάποιος ασχολείται με τη γλώσσα μας.
Ξαναedit : Δυστυχώς, τώρα που το ξανασκέφτομαι, δεν είναι απαραίτητο να είναι κανόνας ειδικά για τη δική μας γλώσσα, απλά δέχεται πρώτο χαρακτήρα ως κεφαλαίο, λόγω του γενικού -μάλλον- κανόνα για κεφαλαίο μετά από τελεία.
Το Orthos είναι επέκταση του LibreOffice και έχει δικό του λεξικό. Τα αντίστοιχα του Hunspell θα τα βρεις στο /usr/share/hunspell/.
Παραθέτω από ένα (παλιό) README για τα Ελληνικά στο Hunspell (έμφαση δική μου):
This variation copes correctly with fully capitalized greek words. Penalty for this, is the increase of proposed words and bigger vocab size.
Αν υπήρχε τρόπος να προσθαφαιρείται η στίξη κατά το δοκούν, σίγουρα θα τον είχαν εφαρμόσει για πολύ πιο περίπλοκες γλώσσες (π.χ. Κροατικά, Πολωνικά κλπ.), δε νομίζεις. Η σκληρή πραγματικότητα είναι ότι πρέπει να κάτσει κάποιος και να βάλει όλες τις λέξεις μία-μία. Η τελευταία φορά που έγινε αυτό για τα Ελληνικά ήταν (μάλλον) το 2015.
Αν μια λέξη δεν υπάρχει καθόλου στο λεξικό, προφανώς θα προτείνει την πλησιέστερη. Το πώς θα την αφήσει χωρίς τόνο είναι το πρόβλημα, καθώς και το πότε θα πρέπει να βάζει τόνο στα κεφαλαία. Δεν υπάρχει τέτοια δυνατότητα απ’ όσο ξέρω.
Το θέμα είναι ποιοι ασχολούνται. Σίγουρα όχι οι Άγγλοι/Γάλλοι/Πορτογάλοι, σωστά; Κάποιος που α) ξέρει καλά τη γλώσσα και β) θέλει να τη γράφει θα ασχοληθεί.
Για να ευθυμήσουμε λίγο, δεν υπάρχει στον πλανήτη καλύτερος «δολοφόνος» των Ελληνικών από τους ίδιους τους Έλληνες.
Θυμάμαι πως πριν από κάμποσο καιρό υπήρχε μια σχετιική γκρίνια, επειδή όταν δούλευε ο ορθογράφος σε μία γλώσσα και έγραφες στο ίδιο κείμενο και σε δεύτερη, δεν μάρκαρε τα λάθη της άλλης.
Με το λεξικό που αναφέρω, αυτό δεν συμβαίνει, μαρκάρει ταυτόχρονα και τις δύο γλώσσες.
Έχω βάλει αυτά τα επιπλέον πακέτα:
οπότε κοίταξα εκεί, δεν έψαξα στα του Hunspell.
Δυστυχώς ξέρω μόνο Ελληνικά και Αγγλικά, οπότε δεν έχω ιδέα αν υπάρχουν άλλες γλώσσες στις οποίες χρειάζεται να αφαιρεθεί επιλεκτικά η στίξη, αλλά δεν έχω λόγο να αμβισβητήσω αυτό που λες. Το ερώτημα που τίθεται εδώ όμως, είναι αν όντως γνωρίζουν τον κανόνα μας. Επίσης δεν έχω χρόνο αυτή τη στιγμή να διαβάσω τα links, θα το κάνω σίγουρα. Όσο για την προσθήκη λέξεων, γράφω λίγο παρακάτω.
Εκτός από το διαζευκτικό “ή”, δεν νομίζω να υπάρχει άλλη λέξη που παίρνει τόνο στα κεφαλαία (και βέβαια τα αριθμητικά που ανέφερες, όπου εκεί όμως πιο σωστά μπαίνει άλλη στίξη π.χ. ΚΑ’ και όχι ΚΆ). Αυτό βρήκα και ψάχνοντας: https://koutrozi.gr/syggrafiko-ergo/54-kanones-tonismoy
Δεν έχεις άδικο, ούτε πολυασχολούμαστε και όντως είμαστε οι χειρότεροι “δολοφόνοι” της γλώσσας μας. Το κατά πόσο αυτό είναι ευτράπελο ή τραγικό, είναι άλλο θέμα
Τεσπα.
Πήρα το αρχείο που ανέφερα παραπάνω
/usr/lib/libreoffice/share/extensions/orthos-el_GR-en_US/dicts/el_GR-en_US.dic
και το αντέγραψα στη επιφάνεια εργασίας. Έχει 910407 εγγραφές, από τις οποίες οι 163240 είναι Αγγλικές λέξεις. Οι υπόλοιπες είναι Ελληνικές. Μέγεθος περίπου 20ΜΒ.
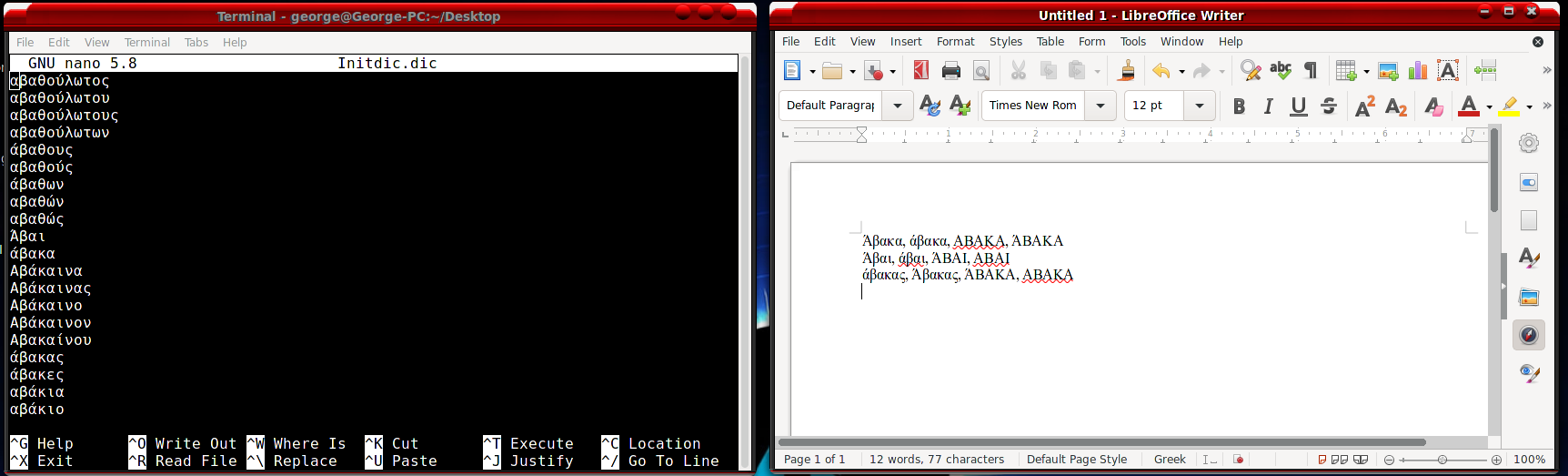
Το μετονόμασα, και μετά το πέρασα απ τον παρακάτω κώδικα
ο οποίος φτιάχνει ένα καινούργιο αρχείο με όλες τις υπάρχουσες λέξεις του αρχικού, προσθέτοντας όσες Ελληνικές υπήρχαν στο αρχικό, αλλά σε άτονα κεφαλαία. Αφού μετονόμασα το αρχικό αρχείο στον αρχικό φάκελο μη γίνει καμιά στραβή, έβαλα αυτό στη θέση του.
Το αποτέλεσμα είναι κάτι τέτοιο :
Τα “πέναλτι” βέβαια αναφέρθηκαν ήδη (1739194 εγγραφές, αρχείο σχεδόν διπλάσιο σε μέγεθος). Δουλεύει μεν, δεν μαρκάρει τις λέξεις με κεφαλαία χωρίς τόνο, αλλά, όπως έγραψε και ο @konfou, δεν μαρκάρει ούτε τις τονισμένες.
Και βέβαια δεν συζητάμε ότι θα βγει εκτός αν πάρει κανα update το λεξικό.
Η μαζική προσθήκη λέξεων στο λεξικό είναι εφικτή. Αν μπορώ να το (ψευτο)κάνω εγώ που (ψιλο)ξέρω μόνο BASIC, ένας γνώστης μιας μοντέρνας γλώσσας μπορεί να κάνει παπάδες.
Δεν είναι λύση όμως, δυστυχώς.
Γιατί, προφανώς, το αγγλικό λεξικό π.χ. δεν περιλαμβάνει ελληνικές λέξεις. Η “λύση” εδώ είναι μια λίστα που περιέχει λέξεις και στις δύο γλώσσες. Ταυτόχρονος ορθρογραφικός έλεγχος σε πολλαπλές γλώσσες από ένα αρχείο δεν υπάρχει αλλιώς (στο LibreOffice πάντα).
Έλληνες έφτιαξαν τη λίστα, άρα γνωρίζουν. Απλά δε μπορεί να γίνει κάτι άλλο από προσθήκη λέξεων. Αυτή είναι η τεχνολογία και έτσι δουλεύει.
Ποτέ δεν πειράζουμε αρχεία του συστήματος. Στον φάκελο $HOME/.config/libreoffice/4/user/wordbook θα βρεις το αρχείο standard.dic. Αν δεν υπάρχει, δημιουργείται όταν προσθέσεις μια λέξη ως σωστή από τη διεπαφή. Εκεί μπορείς να προσθέσεις τις λέξεις που έφτιαξες. Μην το φτιάξεις χειροκίνητα αυτό το αρχείο γιατί θα του λείπει κάτι στην αρχή και δε θα δουλέψει.
Καλησπέρα και συγνώμη για την καθυστερημένη απάντηση, χρειάστηκε να το ψάξω λίγο.
Πρώτ’ απ’ όλα ευχαριστώ για το tip.
Δυσκολεύτηκα λίγο, γιατί ενώ μεν το αρχείο standard.dic υπήρχε, η απ’ ευθείας επέμβαση από το scriptάκι μου (προφανώς δικό μου λάθος) έφτιαχνε ένα λεξικό που δεν δούλευε. Τελικά, έφτιαξα σκέτο το αρχείο με τις λέξεις και μετά τα συγχώνευσα με cat. Αυτό δούλεψε σαν λεξικό, αλλά παρουσιάστηκε ένα θέμα, που απλώς θα το αναφέρω για την ιστορία.
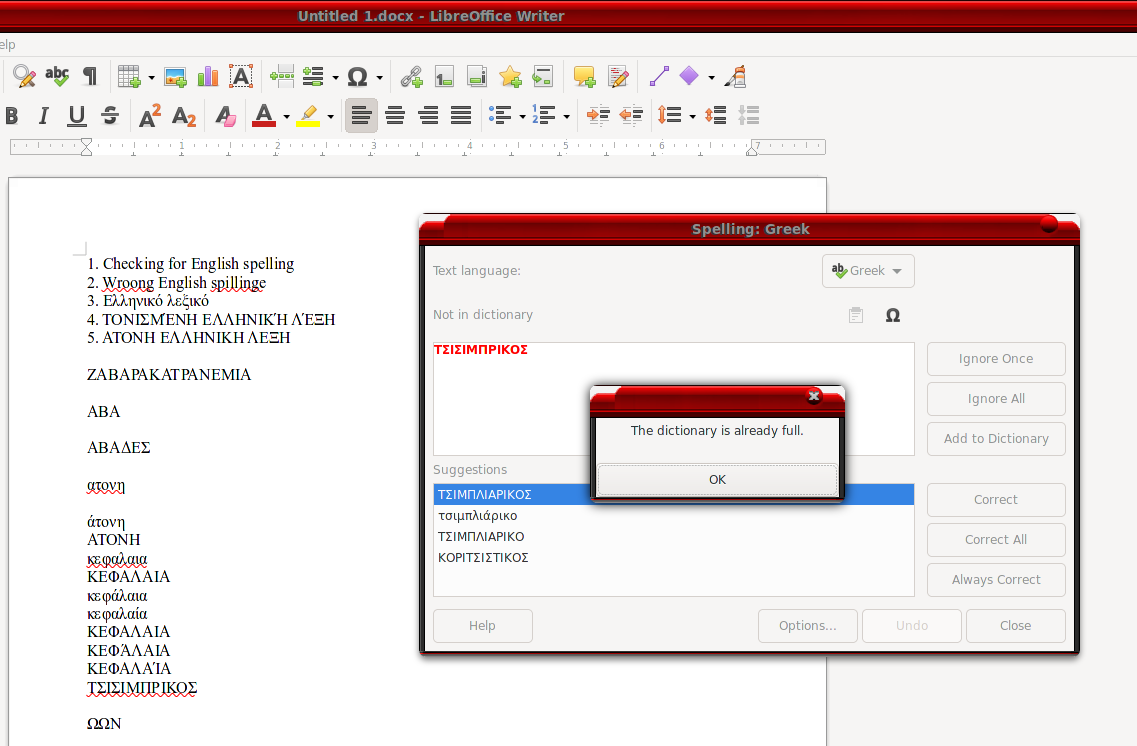
Μετά τη δημιουργία του “μεγάλου” standard.dic (που δουλεύει μέχρι και την τελευταία λέξη που έχει -ΩΩΝ), αν πας να προσθέσεις χειροκίνητα καινούργια λέξη από το writer, σού βγάζει ότι το λεξικό είναι ήδη γεμάτο.
Έψαξα λίγο στο internet για το θέμα, και βρήκα μόνο ένα αναπάντητο ερώτημα
Στη δική μου αρχική προσπάθεια, δεν υφίσταται αυτό (στο standard.dic υπήρχε μόνο η λέξη “ΖΑΒΑΡΑΚΑΤΡΑΝΕΜΙΑ” και η επόμενη (“ΤΣΙΤΣΙΜΠΡΙΚΟΣ”) μια χαρά προστέθηκε).
Ενδεχομένως να υπάρχει όριο μεγέθους, δεν το ξέρω. Το λεξικό όμως πάνω-πάνω έχει έναν αριθμό που είναι το σύνολο των λέξεων που περιέχει. Εικασία κάνω τώρα αλλά αν πρόσθεσες λέξεις με κάποιο script πιθανότατα αυτός ο αριθμός δεν άλλαξε και ίσως αυτό παίζει κάποιο ρόλο.