Γεια σας
Έχω εγκατεστημένο το Linux Mint Cinnamon 20.2 και θέλω να μετατρέψω το κείμενο που υπάρχει σε αρχείο εικόνας, σε επεξεργάσιμο κείμενο, μέσω OCR (Optical Caracter Recognition).
Για το σκοπό αυτό, εγκατέστησα από το Software Manager το προγραμματάκι gscan2pdf.
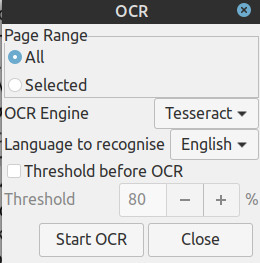
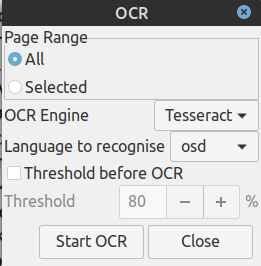
Το πρόβλημα είναι πως όταν επιλέγω Tools > OCR για να μετατρέψει την εικόνα σε επεξεργάσιμο κείμενο, δεν αναγνωρίζει τους χαρακτήρες της Ελληνικής γλώσσας, αλλά το κανει μόνο σε Αγγλικκά και Osd, όπως φαίνεται στις παρακάτω εικόνες.
Μήπως ξέρει κανείς πως μπορώ να προσθέσω στο gscan2pdf, τους Ελληνικούς χαρακτήρες, για να μπορέσω να μετατρέψω Ελληνικό κείμενο;
Ευχαριστώ
Καλημέρα @mintuser
το πακέτο tesseract-ocr-grc πρέπει να το εγκαταστήσεις.
Εφόσον χρησιμοποιείς mint από το τερματικό δίνεις την εντολή: sudo apt install tesseract-ocr-grc
Μετά την εγκατάσταση τα ελληνικά θα πρέπει να εμφανιστούν κανονικά στο πρόγραμμα.
Πράγματι, μετά την εισαγωγή της παραπάνω εντολής στο Terminal, η επιλογή grc εμφανίζεται στις επιλογές του προγράμματος, απλά το πρόβλημα είναι ότι μετά τη μετατροπή (η οποία είναι αρκετά καλή) δεν επιλέγεται όλο το κείμενο της σελίδας, αλλά μόνο μία λέξη κάθε φορά. Μήπως ξέρει κανείς πως επιλέγεται μεγαλύτερο μέρος του κειμένου και όχι μόνο μια λέξη κάθε φορά;
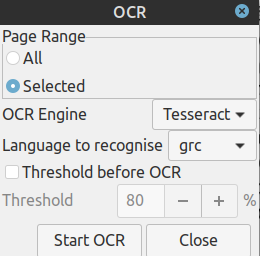
Για να μετατραπεί σε επεξεργάσιμο κείμενο, επιλέγω το μενού Tools > OCR και εμφανίζει το παρακάτω παράθυρο, όπου στο Language to recognise σωστά υπάρχει η επιλογή grc.
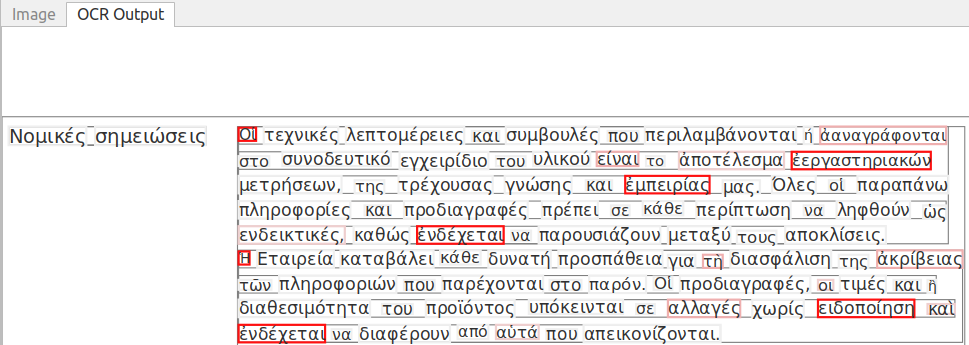
Αφού πατήσω το κουμπί Start OCR μεταβαίνω στην καρτέλα OCR Output και λαμβάνω το αποτέλεσμα που εμφανίζεται στην παρακάτω εικόνα, όπου “υποτίθεται” το κείμενο έχει μετατραπεί σε επεξεργάσιμο.
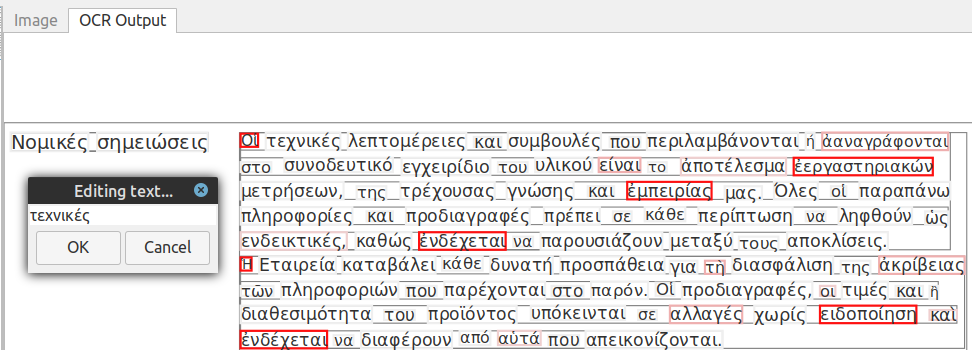
Το πρόβλημα είναι πως όταν θέλω να επιλέξω (με ένα πλαίσιο επιλογής) το “επεξεργάσιμο” πλέον κείμενο, εμφανίζεται το παραθυράκι, Editing text, το οποίο περιέχει μόνο μια λέξη (την πρώτη λέξη) από το κείμενο που προσπάθησα να επιλέξω με πλαίσιο επιλογής, όπως φαίνεται στην παρακάτω εικόνα.
Η ερώτηση είναι: πως μπορώ να επιλέξω εδώ, μεγαλύτερο μέρος του επεξεργάσιμου κειμένου (και όχι μόνο μια λέξη) προκειμένου να το αντιγράψω σε έναν επεξεργαστή κειμένου (π.χ. Text Editor, Libre Office κλπ.) για περαιτέρω επεξεργασία;
Μήπως κάνω εγώ κάποιο λάθος, και αν ναι, ποιο είναι αυτό;
Ευχαριστώ.
To Video που έχεις αναρτήσει παραπάνω δείχνει αυτό που περιγράφεις, δηλαδή τη μετατροπή ενός μη επιλέξιμου .pdf σε επιλέξιμο .pdf. Δυστυχώς δε μας δείχνει πως μετατρέπει το κείμενο που υπάρχει σε ένα αρχείο εικόνας (π.χ. .jpg, .png κλπ.)
Με βάσει το παραπάνω Video δοκίμασα να μετατρέψω κείμενο από:
αρχείο .png, το οποίο όταν (μετά την επιλογή Tools > OCR) το αποθήκευσα σε μορφή .pdf, το κείμενο εξακολουθεί να μην είναι επιλέξιμο.
αρχείο .pdf, το οποίο, εκτός από κείμενο περιέχει και εικόνες. Όταν το άνοιξα στο gscan2pdf, κατά παράξενο τρόπο, άνοιξε μόνο τις εικόνες που υπάρχουν στο αρχικό .pdf, όχι όμως και το κείμενο. Δηλαδή στο gscan2pdf δεν υπάρχει καθόλου κειμενο που θα μπορούσε να μετατραπεί σε επιλέξιμο.
Αυτά τα παράξενα αντιμετώπισα στο gscan2pdf, με αποτέλεσμα να μην έχω τη δυνατότητα μετατροπής σε επεξεργάσιμο/επιλέξιμο κείμενο, ούτε στη μία περίπτωση, ούτε στην άλλη.
Η έκδοση του gscan2pdf είναι η 2.6.4.
Καλημέρα
Σύμφωνα με τις παραπάνω οδηγίες, απεγκατέστησα το grc και εγκατέστησα το ell, όμως στο gscan2pdf δεν μπόρεσα να λάβω επιλέξιμο κείμενο.
Τελικά μόνο με τη δεύτερη περίπτωση κατάφερα να αποκτήσω επιλέξιμο κείμενο.
Σας ευχαριστώ για την ανταπόκριση και σας εύχομαι τα καλύτερα.
Εγώ για αυτή τη δουλειά έφτιαξα ένα docker image βασισμένο στο OCRmyPDF όπου έχω επιλέξει έναν φάκελο που τα αφήνω και μου τα βγάζει σε έναν άλλο έτοιμα από scanned περασμένα OCR ως PDF/A με editable layers.