Φαντάζομαι έχετε χρησιμοποιήσει το jq. Ε λοιπόν, μία νύχτα (σαν όλες τις άλλες) έψαχνα έναν τρόπο να κάνω εξίσου εύκολα parsing ένα html document, και έπεσα πάνω στο GoQuery.
Θα σας δείξω το παράδειγμα που έχουν το github, το οποίο κάνει parsing το website https://www.metalsucks.net/

Εστω λοιπόν ότι θέλω να κάνω parse την στήλη με τα Reviews. Θέλω λοιπόν:
- Να κάνω parse και τα 5 reviews
- Το όνομα της μπάντας
- Το μουσικό άλμπουμ αυτής
Πάμε να κατασκευάσουμε το Query λοιπόν:
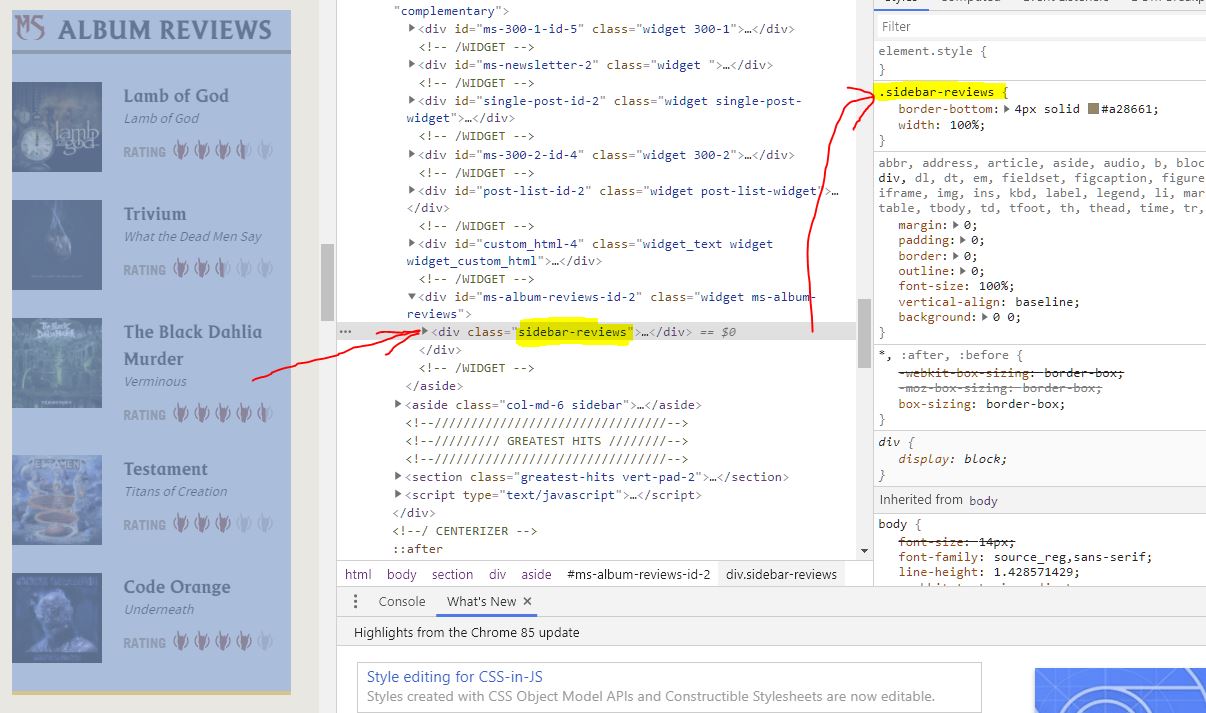
Πρώτο: .sidebar-reviews.
Συνεχίζουμε πιο μέσα:

Δεύτερο:
article όπου έχουμε 5 τέτοια, όσα είναι δηλαδή και τα reviews. Αρα τώρα μένει να βρούμε για το καθένα από αυτά το ονομα της μπάντας και το άλμπουμ.

Κάθε ένα έχει μέσα σου ένα ακόμα
div που λέγεται content-block. Οπότε αφού βρούμε και τα 5 .content-block τότε θέλουμε να ψάξουμε μέσα τους και να βρούμε το a που έχει το όνομα της μπάντας και το ι που έχει το album.
Αρα ο κώδικας θα είναι:
// Το "doc" το HTML document της σελίδας metalsucks.net
doc.Find(".sidebar-reviews article .content-block").Each(func(i int, s *goquery.Selection) {
// Για το καθένα, βρες το όνομα της μπάντας και το άλμπουμ
band := s.Find("a").Text()
title := s.Find("i").Text()
fmt.Printf("Review %d: %s - %s\n", i, band, title)
})
Output:
Review 0: Lamb of God - Lamb of God
Review 1: Trivium - What the Dead Men Say
Review 2: The Black Dahlia Murder - Verminous
Review 3: Testament - Titans of Creation
Review 4: Code Orange - Underneath
Αυτό ήταν :)